在使用深度学习前,我们还是要知道我们已经掌握了什么工具,已经解决了什么问题,这里就是学习这方面知识的总结,当然主要关注的是图像分类问题。
# 常用深度神经网络
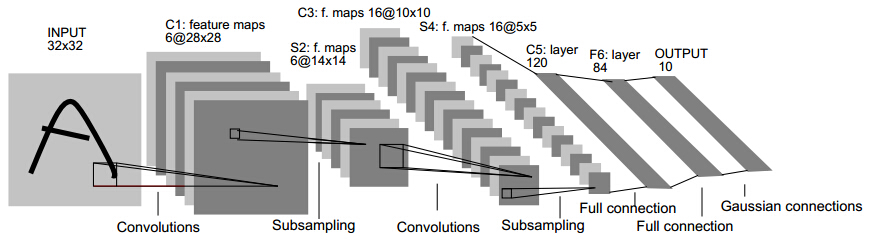
## LeNet
最早的CNN网络,它能够识别0~9的手写数字,但是准确率与SVM相比,还是稍有逊色的。
## AlexNet
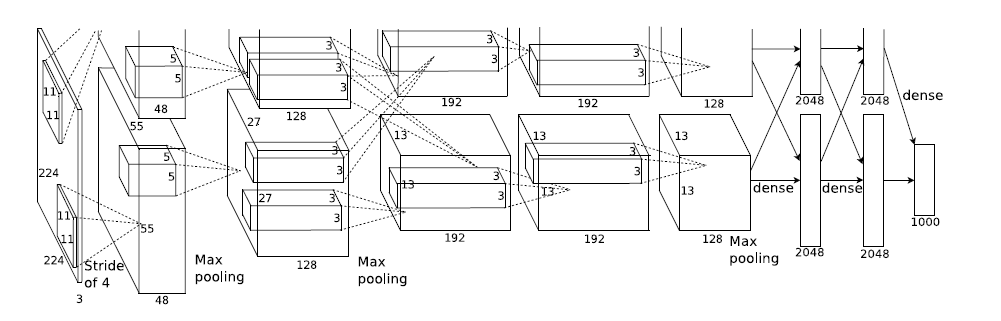
这个模型获得了2012年Imagenet比赛的冠军。这个模型的意义比后面那些模型都大很多,首先它证明了CNN在复杂模型下的有效性,然后GPU实现使得训练在可接受的时间范围内得到结果,顺便推动了有监督DL的发展;其次,它首创性的引入了不同以往的激活函数——ReLU;最后,它提出了一种Dropout的方法来防止过拟合。
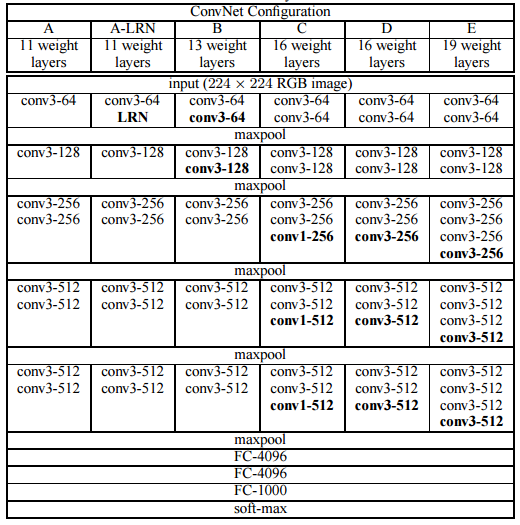
## VGGNet

它的主要创新是将size比较大的filter拆分成几个小的filter的级联。达到的效果是将错误率由AletNet的16.4%降低到了7.3%。
它的详细组成:
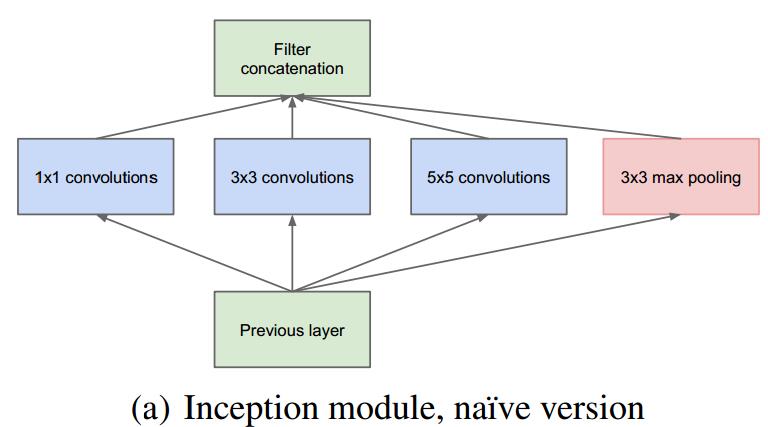
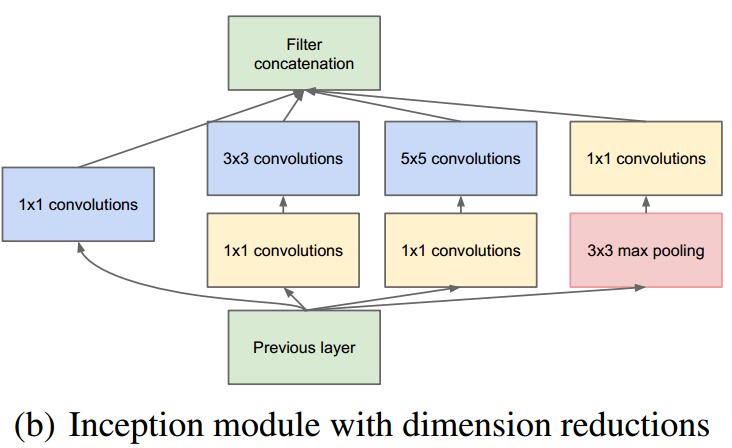
## GoogLenet
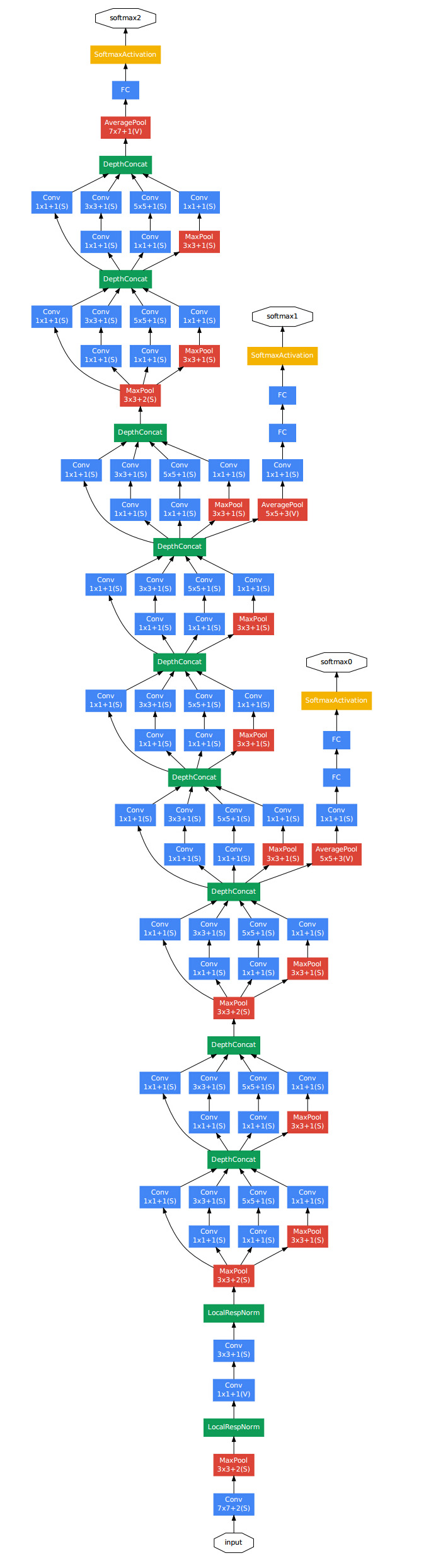
听名字就知道是由Google提出的,它的创新点在于:
- 由于稀疏结构在BLAS和CuBlas上的计算性能不是最优的,使用密集计算来模拟稀疏结构:
- 使用network in network来减少计算量:
## ResNet

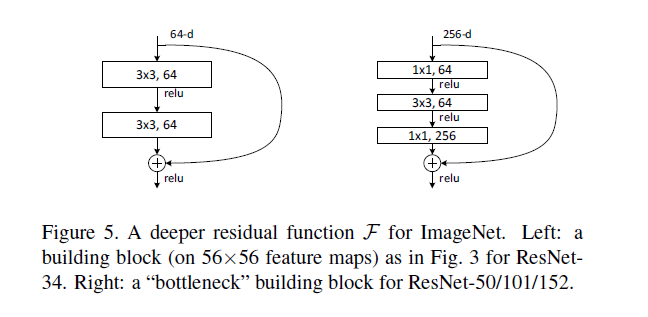
这个模型是由微软提出的,它在imagenet上的错误率是3.57%,是目前最高的。这个模型的创新点在于加入skip网络,使用训练很深的网络成为可能。同时,这个模型也是所有模型中最深的,有152层。
# 网络训练的指导思想
1. 避免表达瓶颈,特别是在网络靠前的地方。 信息流前向传播过程中显然不能经过高度压缩的层,即表达瓶颈。从input到output,feature map的宽和高基本都会逐渐变小,但是不能一下子就变得很小。比如你上来就来个kernel = 7, stride = 5 ,这样显然不合适。
另外输出的维度channel,一般来说会逐渐增多(每层的num_output),否则网络会很难训练。(特征维度并不代表信息的多少,只是作为一种估计的手段)
这种情况一般发生在pooling层,字面意思是,pooling后特征图变小了,但有用信息不能丢,不能因为网络的漏斗形结构而产生表达瓶颈, 解决办法是作者提出了一种特征图缩小方法,更复杂的池化。
2. 高维特征更易处理。 高维特征更易区分,会加快训练。
3. 可以在低维嵌入上进行空间汇聚而无需担心丢失很多信息。 比如在进行3x3卷积之前,可以对输入先进行降维而不会产生严重的后果。假设信息可以被简单压缩,那么训练就会加快。
4. 平衡网络的宽度与深度。
在使用深度学习前,我们还是要知道我们已经掌握了什么工具,已经解决了什么问题,这里就是学习这方面知识的总结,当然主要关注的是图像分类问题。
常用深度神经网络
LeNet
最早的CNN网络,它能够识别0~9的手写数字,但是准确率与SVM相比,还是稍有逊色的。

AlexNet

这个模型获得了2012年Imagenet比赛的冠军。这个模型的意义比后面那些模型都大很多,首先它证明了CNN在复杂模型下的有效性,然后GPU实现使得训练在可接受的时间范围内得到结果,顺便推动了有监督DL的发展;其次,它首创性的引入了不同以往的激活函数——ReLU;最后,它提出了一种Dropout的方法来防止过拟合。
VGGNet

它的主要创新是将size比较大的filter拆分成几个小的filter的级联。达到的效果是将错误率由AletNet的16.4%降低到了7.3%。
它的详细组成:

GoogLenet

听名字就知道是由Google提出的,它的创新点在于:
- 由于稀疏结构在BLAS和CuBlas上的计算性能不是最优的,使用密集计算来模拟稀疏结构:
- 使用network in network来减少计算量:


ResNet


这个模型是由微软提出的,它在imagenet上的错误率是3.57%,是目前最高的。这个模型的创新点在于加入skip网络,使用训练很深的网络成为可能。同时,这个模型也是所有模型中最深的,有152层。
网络训练的指导思想
避免表达瓶颈,特别是在网络靠前的地方。 信息流前向传播过程中显然不能经过高度压缩的层,即表达瓶颈。从input到output,feature map的宽和高基本都会逐渐变小,但是不能一下子就变得很小。比如你上来就来个kernel = 7, stride = 5 ,这样显然不合适。
另外输出的维度channel,一般来说会逐渐增多(每层的num_output),否则网络会很难训练。(特征维度并不代表信息的多少,只是作为一种估计的手段)
这种情况一般发生在pooling层,字面意思是,pooling后特征图变小了,但有用信息不能丢,不能因为网络的漏斗形结构而产生表达瓶颈, 解决办法是作者提出了一种特征图缩小方法,更复杂的池化。
高维特征更易处理。 高维特征更易区分,会加快训练。
可以在低维嵌入上进行空间汇聚而无需担心丢失很多信息。 比如在进行3x3卷积之前,可以对输入先进行降维而不会产生严重的后果。假设信息可以被简单压缩,那么训练就会加快。
平衡网络的宽度与深度。